杠杆炒股,股票融资!


本说明由哥伦比亚大学周瑜(Zhou (Jo) Yu)及Arklex AI团队撰写,系统筹议了AI智能体(AI Agents)的演进、关节本事与明天发展标的。
在东说念主工智能赶紧发展确当下,AI 智能体正迟缓成为备受注重的焦点。从传闻东说念主物比尔・盖茨到闻明学者吴恩达、山姆・奥特曼,他们齐对 AI 智能体的后劲奉求厚望,以为其将掀翻规画领域继图形用户界面之后的又一场首要改革,引颈 AI 赢得纷乱跳动。那么,AI 智能体究竟是什么?它又有着若何的神奇之处呢?
AI 智能体:智能交互新范式
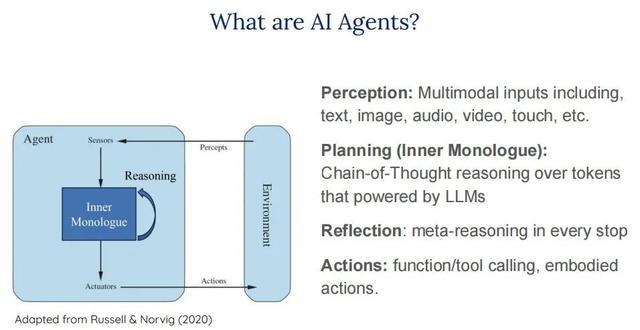
AI 智能体是一种简略感知环境、进行想考和推理、作念出决策并奉行相应行为的东说念主工智能系统。它就像是领有 “奢睿大脑” 的数字精灵,不错给与文本、图像、音频等多种模态的输入信息,如同东说念主类通过各式感官感知宇宙雷同。接着,借助大说话模子(LLM)的强项能力,智能体简略进行想维链推理,联想出行为步骤,这一过程如同东说念主类在面对问题时想考处置有联想。况兼,智能体还具备反想能力,简略凭证行为的收尾进行元推理,束缚优化我方的步履。
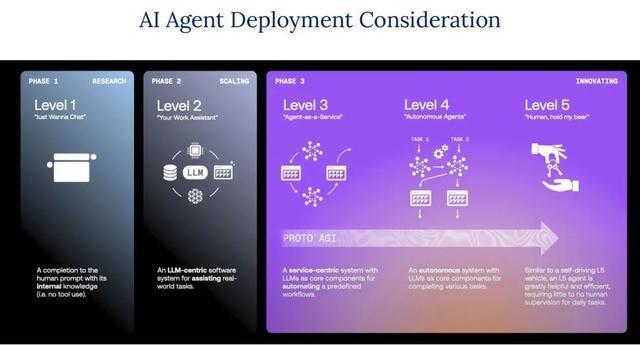
从应用层面来看,AI 智能体的发展可分别为多个阶段。开首是 “Just Wanna Chat” 阶段,智能体仅能精炼地基于本身学问申报东说念主类辅导,如归拢个学问储备有限的聊天伙伴。跟着发展,参加 “Your Work Assistant” 阶段,它演酿成以 LLM 为中枢的软件系统,能扶持完成现实宇宙的任务,举例匡助东说念主们处理使命中的文档撰写、数据整理等事务。再进一步,“Agent-as-a-Service” 阶段的智能体成为以处事为中心的系统,能自动化奉行预界说的使命经由,大大提高使命遵循。更高档的 “Autonomous Agents” 阶段,智能体具备高度自主性,在宽泛任务中简直无需东说念主类监督,如归拢个可靠的使命伙伴。而最瞎想的 “Human, hold my beer” 阶段,智能体访佛达到 L5 级自动驾驶水平的系统,好意思满竟然的自主决策和行为,在复杂环境中无邪应答各式任务。
模子自我培植:解锁智能新高度
在 AI 智能体的发展进度中,模子自我培植至关病笃。以往询查发现,通过辅导进行自我培植的步骤对微型说话模子(LM)成果欠安,微型 LM 存在无法通过辅导好意思满自我培植,也难以从 LLM 的示范中学习 “自我培植” 能力等问题。
为处置这些清苦,询查东说念主员提议了创新步骤。他们把 “自我培植” 视为一个可学习的任务,将 LLMs 或 Python 剧本手脚老师模子。具体操作中,先让微型 LM 尝试处置问题,老师模子凭证尝试收尾给出反映并修改,之后把这种互动素质再行用于教育微型 LM。这一过程就像是学生在敦厚的指令下束缚矫正我方的解题步骤。通过这种表情生成 “自我培植” 数据,再欺骗这些数据教育微型 LM,显赫培植了模子的性能。
在多步算术、单词排序、日历会通和逻辑演绎等复杂任务测试中,收受这种步骤教育的模子推崇出色。比如在多步算术任务上,经过屡次迭代教育的模子,准确率大幅提高。这标明让模子在莫得东说念主类监督的情况下培植性能是可行的,不外现在该步骤也存在一定局限,比如需要强项的剪辑 LLM 进行监督。
树搜索战略:增强模子决策力
很多对话任务本体上是决策过程,为培植模子在这些任务中的决策能力,询查东说念主员引入了树搜索战略。鉴戒海外象棋等游戏中的前瞻搜索想想,在对话决策过程中,模子不错通过树搜索来探索多种可能的行为有联想。具体来说,配资公司便是借助 LLM 来搜索有远景的行为、模拟行为收尾、评估行为质料,并更新对每个行为质料的预计。

以劝说任务为例,询查东说念主员使用 “Prompt-Based Monte-Carlo Tree Search for Goal-oriented Dialogue Policy Planning”(GDP-Zero)步骤,在劝说东说念主们向慈善机构捐钱的任务中,该步骤生成的战略比基础 LLM 更具劝服力,提高了对话任务的到手率。这一战略不仅使聊天机器东说念主的捐钱概率、增强捐钱意愿、提议有劲论据等方面推崇更优,还能幸免过度殷切地提议捐钱肯求,收受更均衡的战略,会通热沈和逻辑诉求,从而更好地达成劝说指标。不外,现在该战略在对话任务以外的膨胀应用,以及若何将矫正后的步履通过教育反映到模子中,也曾有待处置的问题。
强化学习与探索式学习:运转智能体进化
在与规画机交互的视觉说话模子(VLM)任务中,询查东说念主员濒临着纷乱挑战,因为传统 VLM 预教育并未波及与规画机的交互。为培植智能体在这类任务中的推崇,询查东说念主员提议了两种关节步骤:基于对比自反想的蒙特卡洛树搜索(R-MCTS)和探索式学习。

R-MCTS 在奉行任务时,通过树搜索寻找最优行为轨迹,任务完成后进行对比自反想,分析行为的优劣,从而矫正明天的奉行成果。在 VisualWebArena 和 OSWorld 等基准测试中,R-MCTS 推崇不凡,超过了其他搜索算法,在 VisualWebArena 上达到了新的最优收货,在 OSWorld 上也极具竞争力。探索式学习则通过对树遍历进行教育,让智能体在探索、评估和回溯过程中学习,使 GPT-4o 在经过 R-MCTS 树的探索式学习后,即使不借助搜索算法增强,也能展现出规画膨胀的特点,显赫培植了智能体在教育阶段的性能。
明天瞻望:机遇与挑战并存
AI 智能体的发展远景无边,但也濒临诸多挑战。在本事层面,尽管赢得了不少进展,但仍需进一步提高智能体的自主性、泛化能力和学习遵循。举例,减少对树搜索的依赖,探索强化学习等其他步骤,以优化智能体的决策过程;欺骗模子预测适度(MPC)步骤,裁汰与环境交互的老本,提高智能体在复杂环境中的适合性。在执行应用中,AI 智能体要好意思满更平庸的应用,需要处置与现存系统的集成问题,确保其能与不同的软件和硬件平台兼容。同期,还需关爱数据阴私和安全问题,保险用户信息不被流露和浮滥。
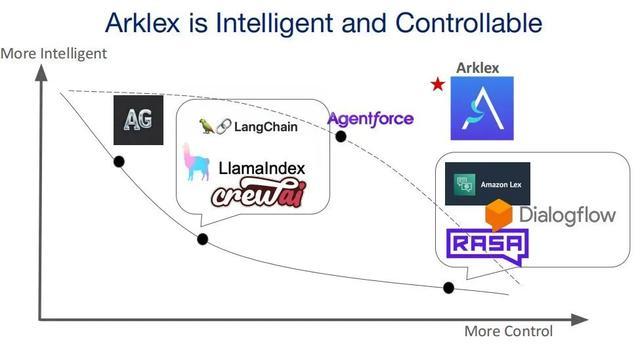
Arklex 作为一个创新的组织框架,为 AI 智能体的发展提供了新的想路。它撑合手混相宜度,使智能体简略凭证用户需乞降构建者指标无邪应答各式任务;通过任务组合,将复杂的现实任务拆解为可复用的模块,提高奉行遵循和膨胀性;强调东说念主类侵犯,确保关节决策的准确性和用户偏好的优先性;还撑合手合手续学习,让智能体在不拒却互中进化,保合手与动态环境的联系性和有用性。与其他框架比较,Arklex 在开源性、混相宜度、任务组合、东说念主类侵犯和合手续学习等方面具有私有上风,为 AI 智能体的发展拓荒了新的标的
