杠杆炒股,股票融资!

剪辑:Panda
事物齐有多面性,正如水,既能载舟,亦能覆舟,还能煮粥。强化学习亦然如斯。它既能匡助 AlphaGo 打败顶级围棋棋手,还能匡助 DeepSeek-R1 得回刚劲的推贤慧商,但它也可能被坏心使用,成为舛误 AI 模子的过劲火器。
近日,威斯康星大学麦迪逊分校的一个接头团队发现,不错通过强化学习对模子抓行有用的黑盒灭绝舛误(Black-Box Evasion Attacks)。接头团队暗示:「从安全角度来看,这项使命展示了一种刚劲的新舛误序论,即使用强化学习来有用且大界限地舛误机器学习模子。」

底下咱们就来浅显望望这项接头。
领先,为什么要接头如何舛误模子?谜底当然是为了安全。
当前 AI 发展迅猛,各式应用层见错出,何况还是给好多领域带来了宏大变革。而跟着应用的普及,舛误这些模子也逐步开动变得有意可图,其中一类舛误神志是:生成能够乱来 AI 模子的输入,从而绕过安全过滤器。这个领域被称为抗争机器学习(AML),接头的是能针对目的模子生成抗争样本的算法。
现存的 AML 一样使用优化算法来最小化施加到输入的变化(称为扰动),使得受害者机器学习模子对带有扰动的输入进行分类时会犯错。不外,时候社区对模子小心和抗争智商的清爽依然有限。
抗争样本生成算法依赖基于梯度的优化,该优化与任何其他信息无关。这些要领无法愚弄从往时的舛误中得回的信息来阅兵对其他数据的后续舛误。
这是 AML 接头中的一个空缺,即接头抗争样本是否不错学习 —— 舛误的有用性和成果是否会跟着申饬的累积而提高。那么,对受害者模子拜谒权限有限(称为黑盒拜谒)的敌手能够大界限生成抗争样本(举例永别式拆开作事舛误)吗?
刚毅化学习引入抗争舛误
磋商到最近强化学习的得胜,该团队揣测能否将 AML 敌手建模为强化学习智能体 —— 这么一来,或者能让舛误计策跟着时辰而变得越来越高效和有用。
他们按照这个念念路进行了接头,提倡了基于强化学习生成抗争样本的舛误要领并对其进行了评估。
他们发现,当把敌手建模成强化学习智能体时,其就能学习到哪些扰动最能乱来模子。一朝学会了计策,敌手就会使用该计策生成抗争样本。因此,抗争性智能体无需崇高的梯度优化即可完成对模子的舛误。
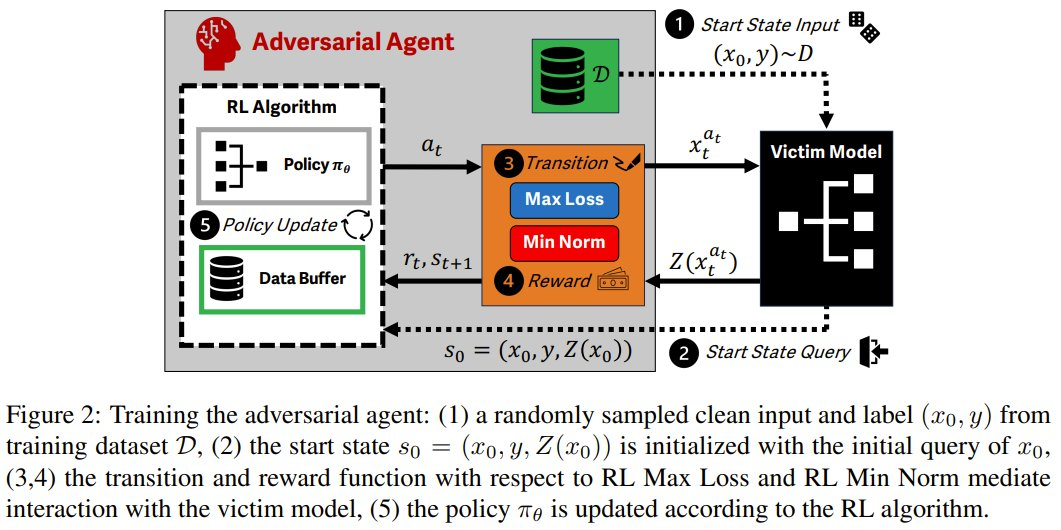
具体来说,该团队将抗争样本生成过程建模成了马尔可夫有缠绵过程(MDP)。如斯一来,炒股配资便不错芜俚地使用强化学习,杀青对舛误的底层语义的封装:输入样本和受害者模子输出为情状,扰动为看成,抗争性目的的各别为奖励。
该团队提倡了两种强化学习舛误要领:RL Max Loss 和 RL Min Norm。它们对应于两类传统的 AML 算法。

其舛误进程是这么的:领先使用一个强化学习算法来考验智能体,然后在计策评估成就中使用舛误来生成抗争样本。
执行评估
为了考证强化学习舛误要领的有用性,该团队在 CIFAR-10 图像分类任务上,使用一个 ResNet50 受害者模子进行了评估,使用的算法是近端计策优化(PPO)。该团队在此框架下进行多法式评估,评估本色包括 (a) 学习、(b) 微斡旋 (c) 相干于已知要领的准确度。
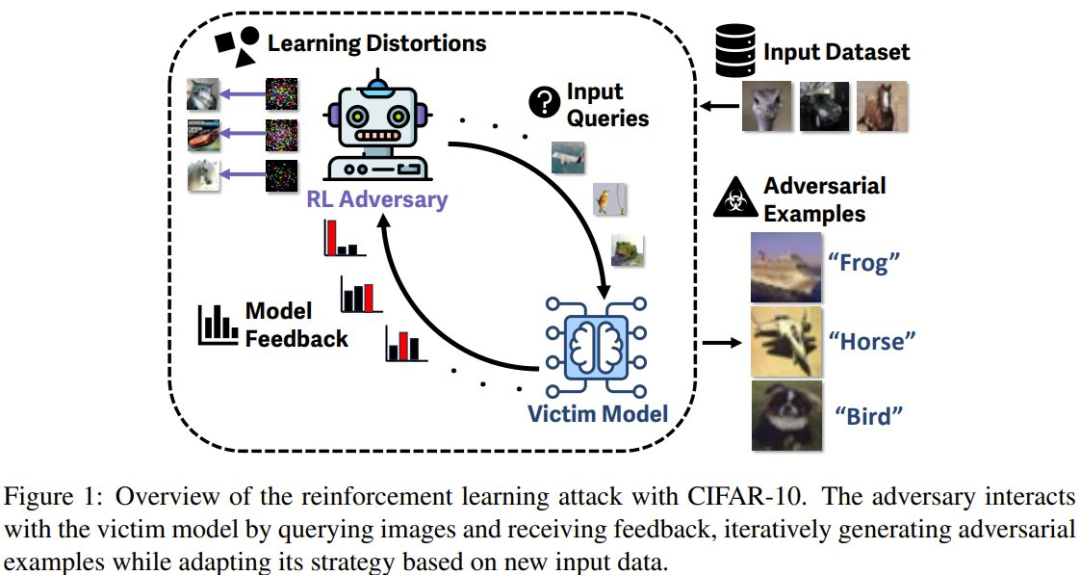
领先,他们评估了强化学习智能体能否学习抗争样本。换句话说,强化学习能否在考验过程中提高抗争样本的有用性和成果?
遣发放现,RL Max Loss 和 RL Min Norm 舛误齐会加多考验过程中的平均酬劳,从而考证了强化学习时候学习任务的智商。
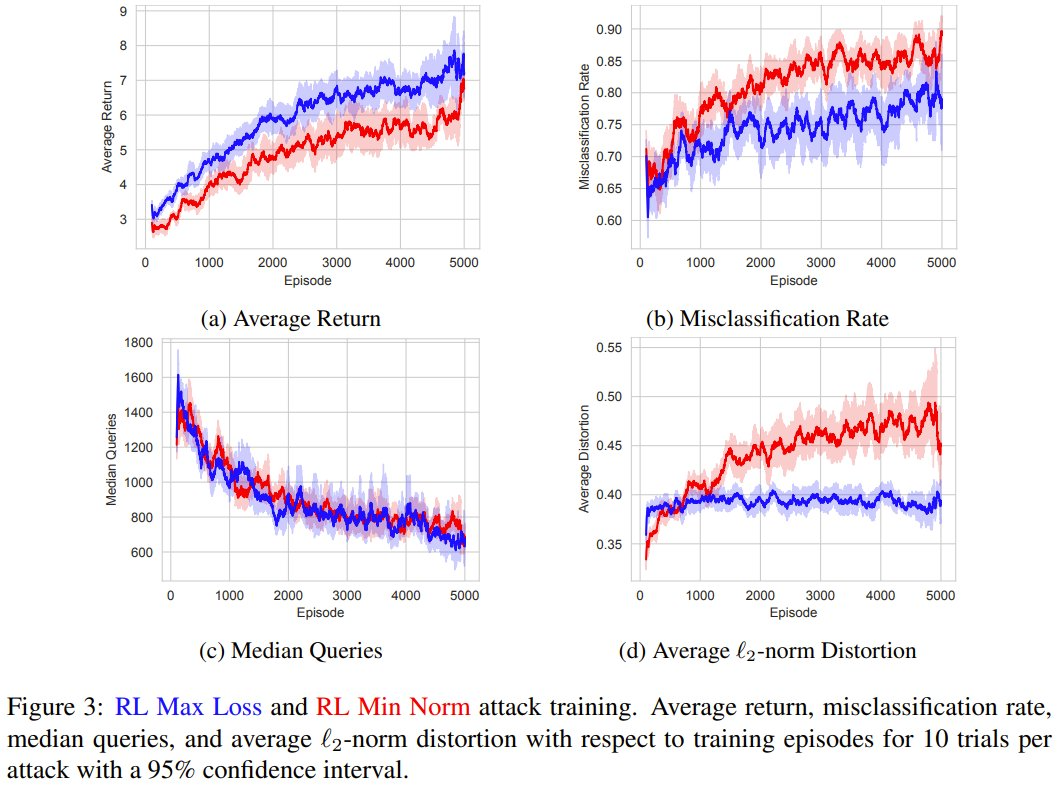
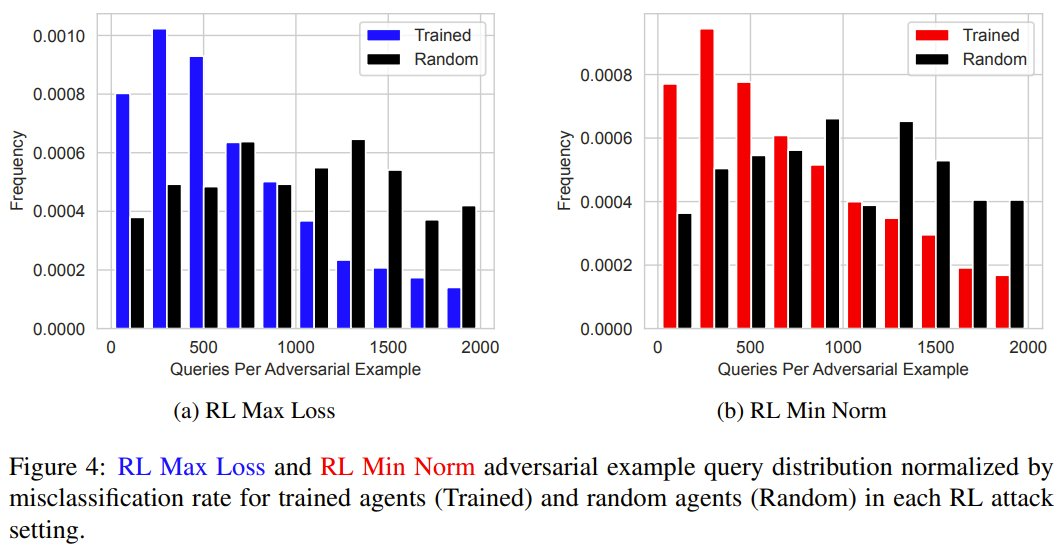
在统统考验过程中,抗争样本的产生速率平均升迁了 19.4%,而与受害者模子的交互量平均减少了 53.2%。
这些斥逐标明,通过高效地生成更多抗争样本,智能体可在考验过程中变得愈加刚劲。
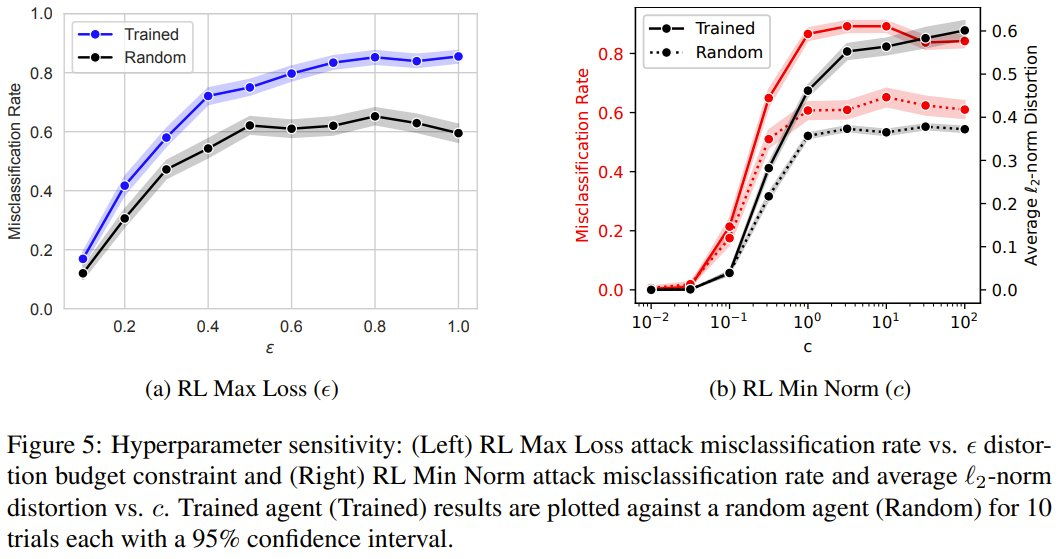
接下来,他们还分析了 RL Max Loss 和 RL Min Norm 中的奖励和调遣超参数会如何影响抗争样本。
ε 参数铁心的是 RL Max Loss 智能体在给定输入上允许的失真量。c 参数铁心的是 RL Min Norm 智能体因裁减受害者模子置信度而不是最小化失真而得回奖励的进度。
固然考验智能体不错提高这两种舛误的性能,但他们的接头标明这也取决于 ε 和 c 的选择。具体执行中,他们字据均衡抗争性目的的敏锐性分析选择了 ε = 0.5 和 c = 1.0。当敌手使用这些舛误时,为了达到预期目的,必须在舛误之前磋商它们。
临了,该团队还评估了经过考验的智能体如何将抗争样本泛化到未见过的数据,以及它相干于世俗使用的基于优化的 SquareAttack 算法的进展如何。
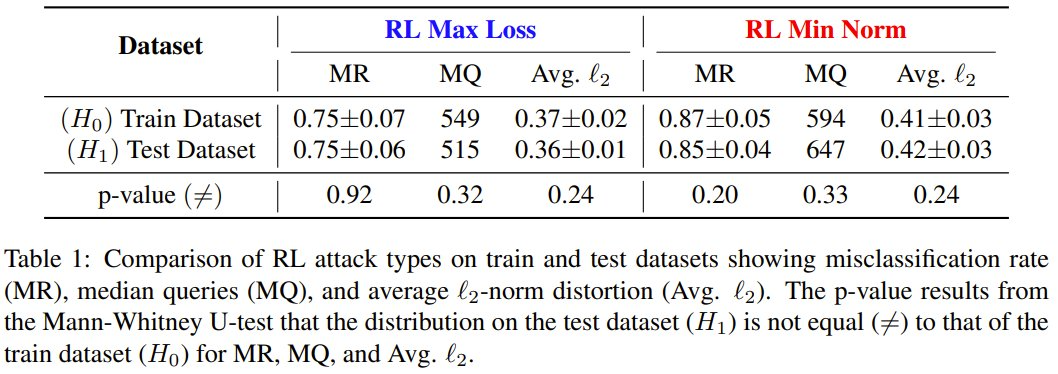
在考验外的未见过的数据集上,考验后的智能体的荒唐分类率、中位数查询和抗争样本的平均失真齐落在考验抗争样本的永别中。
在与 SquareAttack 的黑盒比拟中,他们将 5000 episode 的强化学习舛误与其它 SOTA 时候进行了比拟,斥逐标明学习抗争样本让强化学习舛误能够生成多 13.1% 的抗争样本。
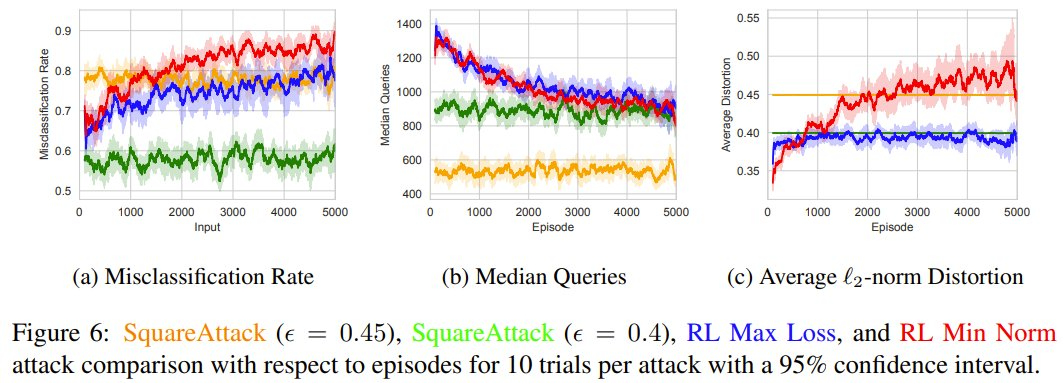
这些斥逐标明,要是敌手通过强化学习要领学习抗争样本,会比现存要领更有用。
你怎么看待这项接头,咱们又该怎么小心敌手的强化学习舛误呢?
