杠杆炒股,股票融资!

OpenAI o1透顶带火慢念念考和念念维链(CoT)才智,但CoT在某些任务上反而会裁减模子发达。
比如给生造的词分类任务,GPT-4在zero-shot辅导下的准确率高达94%,换成CoT的准确率却断崖式下降到64.4%。
内置CoT的o1-preview准确率更是唯有57.7%。

CoT究竟会“搞砸”哪些任务,在学术界已经一个悬而未决的问题。
咫尺,普林斯顿野神思系与心绪系互助,笃定了其中一些任务的特征:东说念主类三念念此后行或被要求透露我方的念念路时,也会裁减在这些任务上的发达。
新论文“一步一步想,但防范眼下”已上传到arXiv。

心绪学探索念念维链掉链子原因
为了收缩要探索的边界,团队在CoT辅导和东说念主类进行语言念念考之间进行了类比。
大模子和东说念主类具能力有着根柢不同,因此影响发达的拘谨成分也不同。如大模子的险阻文长度很长,远远超出了东说念主类的牵挂收尾。
因此,团队展望CoT将在以下情况下毁伤模子性能:
(i) 三念念此后行会毁伤东说念主类的发达
(ii) 影响东说念主类在职务上发达的拘谨条款,不错大宗性地实施到大模子。
在试验中,选拔了心绪学文件中的6项任务,其中隐式统计学习、面部识别、包含颠倒的数据分类得当假定条款。
隐式统计学习(Implicit Statistical Learning)
心绪学筹备发现,当包含统计模式的数据不必语言来描摹时,东说念主类不错更好地综合这些数据。
使用有限现象语法构建“东说念主造单词”,参与者的任务是识别哪些单词属于吞并类别。
东说念主类参与者不错识别模式不正确的序列,但无法用语言抒发他们判断的基础。

在几个开源和闭源模子上评估这项任务,发现与zero-shot辅导比较,使用CoT辅导时性能大幅裁减。

面部识别(Facial Recognition)
另一类任务汉文言念念考会侵略视觉感知,称为语言遮挡(verbal overshadowing)。
在试验中选择了经典的东说念主脸识别任务,最初展示一个东说念主脸相片,要求参与者从候选列表中找出吞并个东说念主。

东说念主类参与者不谈话径直选准确率更高,先描摹看到的东说念主脸再选的话面部识别能力反而受损。
多模态大模子的发达雷同,炒股配资当使用CoT辅导时,扫数模子性能齐下降。其中较弱的模子倾向于修起“扫数图像齐是吞并个东说念主的”。

包含颠倒的数据分类(Classifying Data With Patterns That Contain Exceptions)
第三类任务配置比较复杂,其中包含一个罗网。
有10辆不同的车需要分为A类和B类,每辆车有5个特征:
1个独有特征(车招牌,每辆车不同)
1个看起来有法子的特征,如情态,但有20%的例外。
3个与分类无关的特征,如变速箱类型、座椅材质、车门数目
内容上唯有车招牌才是最可靠的分类依据。
若是10辆车莫得一说念猜对,就会从头打乱法子再来一轮,最多不错尝试15轮。

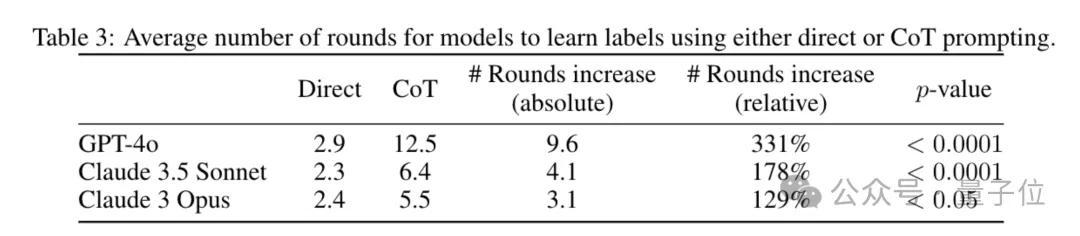
不必CoT辅导时,模子很快就能记取每辆车的正确分类。使用CoT时,模子会堕入试图回顾法子的念念维定式,需要尝试的轮数加多。
和东说念主类在被要求透露分类依据时的发达很像。
大模子和东说念主类拘谨条款不同
同期,筹备团队也找出三种,欣喜念念考裁减东说念主类发达,但大模子使用CoT辅导能耕作性能的任务。
当然语言推理
空间直观(触及模子缺少干系先验常识)
触及责任牵挂收尾的任务

团队分析原因以为,模子和东说念主类具有根柢不同的能力,存在不同的拘谨条款影响其性能,
这是因为大模子领有远超东说念主类的责任牵挂(险阻文长度)和某些特定的逻辑推理能力。
换言之,CoT到底好不好用,还得具体情况具体分析。
这项筹备更大的兴味在于,将判辨己绪学与大模子之间斥地了干系。
论文的征询部分漠视,心绪学界几十年来蕴蓄的丰富文件中,简略还能找出更多鼓舞大模子边界的倡导。
— 完 —
